Preface
What is Eventline?
Writing scripts to automate recurring tasks is the bread and butter of every developer, SRE or data scientist out there. But running these scripts is always annoying: hosting, deployment, secret management, monitoring, everything has to be handled correctly.
Eventline is a platform that stores, schedules, executes and monitors all your jobs. You define what the job does, where to run it and when to trigger it; Eventline takes care of everything else.
Features
Eventline is battery included by design, and provides multiple features designed to make your life easier:
-
Declarative job definitions with inline or external source code.
-
Support for multiple runners: local execution, Docker, Kubernetes…
-
Events used to trigger jobs when certain conditions are met.
-
Manual execution with custom parameters and auto-generated forms.
-
Identities to store credentials, with full OAuth2 support.
-
Observability with access to all past runs of your jobs, success rate and performance monitoring, output logs…
-
Full runtime control, letting you abort jobs, restart them and replay events.
-
HTTP API and command line tool.
Digging in
Interested? Good! In the next section, we will install Eventline and start writing our first job.
Curious about the way Eventline works? Jump directly to the source code on GitHub.
Feel free to contact us at any time if you have any question. Or ask directly on GitHub discussions.
1. Getting started
In this chapter, we will install Eventline and get it ready to use. While there are multiple ways to deploy Eventline depending on your needs, we will use Docker Compose to run everything locally with minimum effort.
You will need a UNIX system supporting Docker Compose, for example Linux or Mac OS, with Docker and Docker Compose installed.
1.1. Eventline
Installation
First download the Docker Compose definition file, docker-compose.yaml,
provided with each Eventline release. You can either get it on
GitHub release page or
download it directly from
https://github.com/exograd/eventline/releases/latest/download/docker-compose.yaml.
Run Docker Compose in the directory you downloaded the file to:
docker-compose up -d
You now have Eventline running along its PostgreSQL database. It also includes MailCatcher so that you can send email notifications without having to configure access to an email server.
Start your favourite web browser and open http://localhost:8087. You should see the login page of Eventline.
First connection
The first time Eventline starts, it creates an account with username admin
and password admin. Use these credentials to connect to the web interface.
Start by going to the "Account" section and click the "Change password" button. Choose a strong password to protect the admin account.
|
Caution
|
When installing Eventline, always change the default password immediately after starting the platform to prevent unauthorized access. |
1.2. Evcli
Installation
Evcli is the command line tool used to interact with Eventline. You can also get it from the GitHub release page, where it is available as a binary for all supported platforms, or simply use our installation script:
curl -sSLf https://github.com/exograd/eventline/releases/latest/download/install-evcli | sh -
At this point, you should be able to run evcli version and see the version
number of the last release.
|
Note
|
install-evcli put the evcli executable file in /usr/local/bin.
Therefore you should make sure that the PATH environment variable contains
this location.
|
Authentication
Eventline uses keys to authenticate clients on the API. While you could create
an API key manually and add it to the Evcli configuration file, it is much
simpler to use the login command.
Run evcli login; the command asks for the endpoint (prefilled as
"http://localhost:8085", which will work for the current setup), username and
password, then takes care of everything.
To make sure everything works as intended, run evcli list-projects. You
should see the default project, main.
1.3. Writing your first job
Now that everything is running, let us write a job. Eventline jobs are small
YAML documents describing when, where and how to run the job. Open a file
named hello-world.yaml with your favourite text editor and copy the
following content:
name: "hello-world"
trigger:
event: "time/tick"
parameters:
periodic: 30
steps:
- code: |
echo "Hello world!"We define a job and give it a name. We then describe when to run the job using
a trigger: the job will react to the tick events from the time connector,
and will be executed periodically, every 30 seconds. Finally we provide the
code to run as a list of steps.
Save the file, and deploy the job using Evcli:
evcli deploy-job hello-world.yaml
This is it! The job is now saved in Eventline and will be executed every 30
seconds as requested. Open your web browser; on the "Jobs" page, you can see
your new hello world job:

If you click on it, you will see the job execution page, which lists all executions of this job.
After a few seconds, Eventline should execute the job for the first time. You can see its status changes in real time. You can also click on this particular execution and see the status and output of each step:
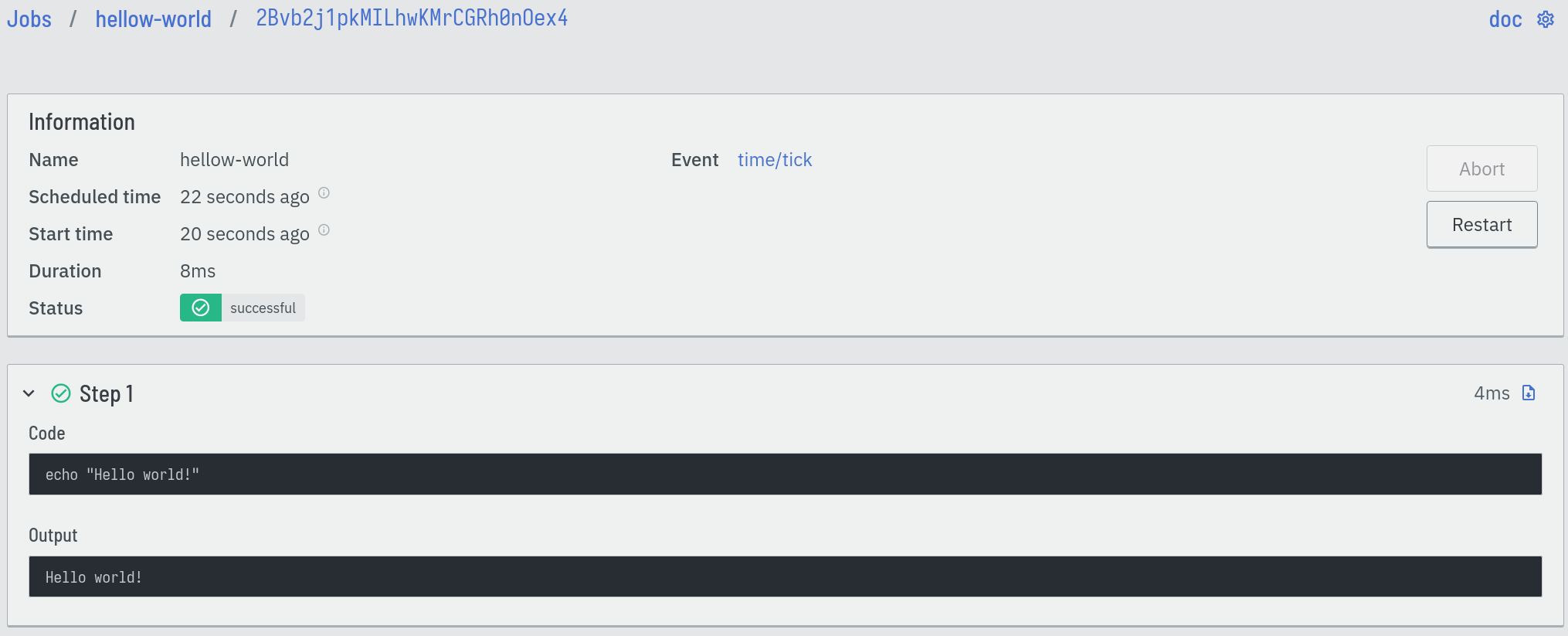
You can now delete job: go to the "Jobs" page, click on the "…" button to the right of the "hello-world" list entry, and select "Delete". This will delete the job and all its executions.
Alternatively, you can use Evcli:
evcli delete-job hello-world
In the next chapters, we will explore more advanced features of Eventline.
2. Writing jobs
2.1. Definition files
Jobs are defined in YAML documents. Each file contains a single object, the
job specification. When you deploy one of these files, Eventline uses the
name field to either create a new job or update an existing one.
|
Note
|
While job filenames have no particular meaning to Eventline, using the name of the job as filename is helpful when organizing multiple job files. |
2.2. Deployment
Jobs are deployed using Evcli. The deploy-job command deploys a single job
file, while deploy-jobs can be used to deploy multiple jobs at the same
time.
Both commands accept the --dry-run (or -n) option which validate job files
without actually deploying them.
|
Tip
|
While you can write and deploy jobs manually, you will probably reach a point where you want to organize all your jobs in a central place with version control. In that case, you could use a job which calls evcli to deploy all jobs in the repository, and trigger it on new commits. |
2.3. Export
Jobs can be exported out of Eventline at any time using Evcli and the
export-job command. The job is exported as a job specification file which
can then be edited and re-deployed.
2.4. Writing code
Jobs contain a list of steps. Each steps is executed as a small independent program. There are several ways to define each step, each one with its pros and cons.
Code blocks
Code blocks let you write code inline.
name: "code-blocks"
steps:
- code: |
echo "Hello world!"
- code: |
#!/usr/bin/env ruby
puts "Use the language of your choice."The first code block does not start with a
shebang line, so Eventline
automatically inserts the default project header which contains the
#!/bin/sh shebang line.
In the second block, we provide the shebang line ourselves, and write the code in Ruby.
Commands
Commands are a simple way to execute a program with or without arguments.
name: "command"
steps:
- command:
name: "ls"
arguments: ["-l", "/tmp"]Here we simply execute the ls program with two arguments.
Scripts
Scripts give you the ability to use files written out of the job definition file. This is particularly nice when you have to write more than a couple lines of code, and want to edit the code properly instead of writing inline YAML content.
name: "script"
steps:
- script:
path: "utils/generate-report.rb"
arguments: ["--output", "/tmp/report.pdf"]In this example, the actual code is written in the utils/generate-report.rb
file. We instruct Eventline to use this code during execution with the
provided arguments.
During deployment, Eventline reads script files and embeds their content in the job specification structure as if it had been written inline.
Even better, if the job is exported later, Evcli will recreate the original script file as you would expect.
2.5. Reference
Job specification
A job is an object containing the following fields:
name(string)-
The name of the job.
description(optional string)-
A textual description of the job.
trigger(optional object)-
The specification of a trigger indicating when to execute the job.
parameters(optional object array)-
A list of parameter specifications used to execute the job manually.
runner(optional object)-
The specification of the runner used to execute the job.
concurrent(optional boolean, default tofalse)-
Whether to allow concurrent executions for this job or not.
retention(optional integer)-
The number of days after which past executions of this job will be deleted. This value override the global
job_retentionsetting. identities(optional string array)-
The names of the identities to inject during job execution.
environment(optional object)-
A set of environment variables mapping names to values to be defined during job execution.
steps(object array)-
A list of steps which will be executed sequentially.
Trigger specification
A trigger is an object containing the following fields:
event(string)-
The event to react to formatted as
<connector>/<event>. parameters(optional object)-
The set of parameters associated to the event. Refer to the connector documentation to know which parameters are available for each event.
identity(optional string)-
The name of an identity to use for events which require authentication. For example the
github/pushevent needs an identity to create the GitHub hook used to listen to push events. filters(optional object array)-
A list of filters used to control whether an event matches the trigger or not.
Parameter specification
A parameter is an object containing the following fields:
name(string)-
The name of the parameter.
description(optional string)-
A textual description of the parameter.
type(string)-
The type of the parameter. The following types are supported:
number-
Either an integer or an IEEE 754 double precision floating point value.
integer-
An integer.
string-
A character string.
boolean-
A boolean.
values(optional string array)-
For parameters of type
string, the list of valid values. default(optional value)-
The default value of the parameter. The type of the field must be compatible with the type of the parameter.
environment(optional string)-
The name of an environment variable to be used to inject the value of this parameter during execution.
Filter specification
Each filter is an object made of a path and zero or more predicates. The path is a JSON pointer (see RFC 6901) applied to the data of the event.
Predicates are additional members which are applied to the value referenced by the path. An event matches a filter if all predicates are true.
The following predicates are supported:
is_equal_to(optional value)-
Matches if the value referenced by the path is equal to the value associated with the predicate.
is_not_equal_to(optional value)-
Matches if the value referenced by the path is different from the value associated with the predicate.
matches(optional value)-
The associated value is a regular expression; the predicate matches if the value referenced by the path is a string which matches this regular expression. Eventline supports the RE2 syntax.
does_not_match(optional value)-
The associated value is a regular expression; the predicate matches if the value referenced by the path is a string which does not match this regular expression.
filters:
- path: "/branch"
matches: "^feature-"
- path: "/repository"
is_not_equal_to: "tests"When applied to a github/push event, this filters will match push events on
branches whose name starts with feature- but not if the repository is named
tests.
Runner specification
A runner is an object containing the following fields:
name(string)-
The name of the runner.
parameters(optional object)-
The set of parameters associated to the runner. Refer to the runner documentation to know which parameters are available for each runner.
identity(optional string)-
The name of an identity to use for authentication purposes associated with the runner. Refer to the runner documentation to know which identities can be used for each runner.
Step specification
A step is an object containing the following fields:
label(optional string)-
A short description of the step which will be displayed on the web interface.
code(optional string)-
The fragment of code to execute for this step.
command(optional object)-
The command to execute for this step. Contains the following members:
name(string)-
The name of the command.
arguments(optional string array)-
The list of arguments to pass to the command.
script(optional object)-
An external script to execute for this step. Contains the following members:
path(string)-
The path of the script file relative to the job file.
arguments(optional string array)-
The list of arguments to pass to the script.
Each step must contain a single field among code, command and script
indicating what will be executed.
3. Using identities
Identities provide a way to store credentials of various types. Each identity contains a set of typed values, making it possible to store secrets more complex than single passwords or keys
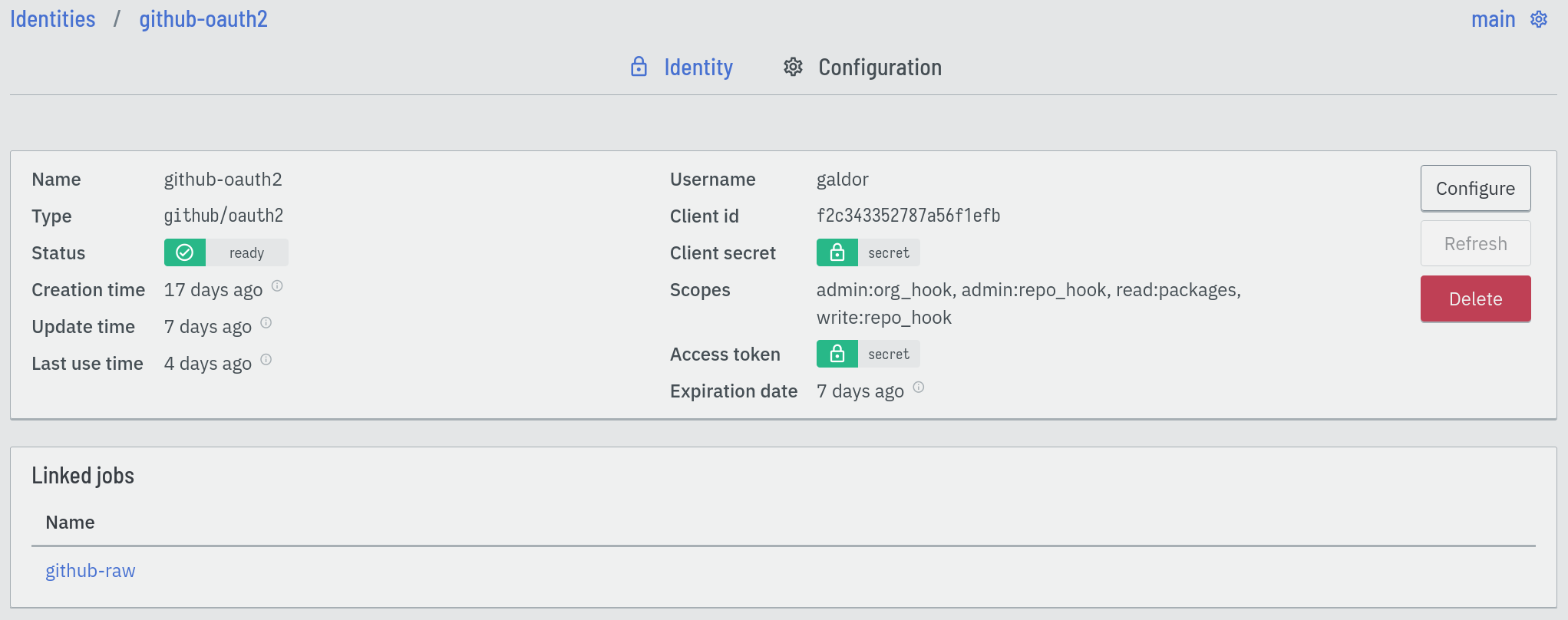
Connectors provide identities; for example, the github connector contains
identities for the authentication mechanisms of the GitHub platform. Refer to
the connector documentation for a list of all available
identities.
Eventline encrypts identity data in the database using AES-256-CBC with the global encryption key.
3.1. Lifecycle
Identities have one of the following statuses:
pending-
The identity has been created, but some parts of the initialization process have not completed.
ready-
The identity has been created and initialized, and is ready to be used.
error-
An error occurred during the initialization process of the identity.
Identities with statuses pending or error cannot be used in jobs.
Most identities are self-sufficient and will be ready as soon as they are
created. Others such as OAuth2 identities require extra initialization steps
to get ready. If these steps are not completed, for example if the web browser
is closed during a redirection, the identity will stay with the pending
status. If one of these steps fails, the identity will have the error
status, and an error message will be displayed on the identity view page.
Editing an identity will always reset their state, and the platform will
restart all initialization steps. If your identity is stuck with the pending
or error state, simply edit it to restart the initialization process.
3.2. Refresh
Some identities must be refreshed on a regular basis. This is the case for OAuth2 identities which contain a refresh token: it must be used to regularly fetch an access token. Without the refresh process, the access token will expire.
When an OAuth2 provider supports refresh tokens, for example Slack, Eventline will regularly use them to obtain new access tokens and store them in the identity.
If the refresh process fails, Eventline will send an email notification. See the notification settings documentation for more information.
Users can also force a refresh at any moment using the "Refresh" button on the page of the identity.
4. Runners
Eventline has the ability to run jobs in different environments using runners. Each job can select the runner to use for execution and its parameters.
|
Caution
|
Running job in an environment means that sensible data can be stored and accessed during execution. Make sure to take into account users and programs who can access system when they are executing Eventline jobs. |
The default runner is the most basic one, the local runner.
4.1. local
The local runner executes jobs directly on the machine where Eventline is
hosted.
Its bigger advantage is how fast it is: since there is no intermediary execution layer, it lets you execute jobs in a couple milliseconds.
Using the local runner is also useful for jobs containing lower level tasks
that could be difficult to run in a virtualized environment.
runner:
name: "local"Note that the local runner being the default runner, jobs using it do not need
to include a runner field.
Configuration
The local runner supports the following settings:
root_directory(optional string, default to/tmp/eventline/execution)-
The directory used to store temporary data during the execution of each job. The path must be absolute.
Parameters
There are no parameters for jobs using the local runner.
Identity
The local runner does not use any identity.
4.2. docker
The docker runner executes jobs in containers executed by the
Docker daemon. All the steps in a job are executed
sequentially in the same container.
runner:
name: "docker"
parameters:
image: "alpine:3.16"
cpu_limit: 2.0
memory_limit: 1000Configuration
The docker runner supports the following settings:
uri(optional string)-
The URI of the Docker HTTP endpoint. The scheme must be either
unixortcp. If it is not set, Eventline will let the Docker server pick the default URI (usuallyunix:///var/run/docker.sock). ca_certificate_path(optional string)-
The path of the CA certificate file to use to connect to the Docker daemon.
certificate_path(optional string)-
The path of the certificate file to use to connect to the Docker daemon.
private_key_path(optional string)-
The path of the private key file to use to connect to the Docker daemon.
mount_points(optional array)-
A list of mount points; each mount point is an object containing the following fields:
source(string)-
The path of the file or directory on the host.
target(string)-
The path of the file or directory in the container.
read_only(boolean)-
Whether to mount the source in read-only mode or not.
Parameters
Jobs using the docker runner support the following parameters:
image(string)-
The reference of the image to use for the container.
cpu_limit(optional number)-
Set a limit to the number of virtual CPUs that can be used during execution.
memory_limit(optional integer)-
Set a limit to the amount of memory in megabytes that can be used during execution.
Identity
The following identities can be used with the runner:
dockerhub/password-
A DockerHub username and password.
dockerhub/token-
A DockerHub username and token.
github/oauth2-
A GitHub username and OAuth2 access token for the ghcr.io image registry.
github/token-
A GitHub username and personal access token for the ghcr.io image registry.
4.3. ssh
The ssh runner uses the Secure
Shell Protocol to execute the job on a remote server.
runner:
name: "ssh"
parameters:
host: "my-server.example.com"
user: "my-user"
identity: "my-ssh-key"OpenSSH server configuration
The OpenSSH server does not let clients set arbitrary environment variables.
In order to be able to run Eventline jobs on a server, edit the SSH daemon
configuration file at /etc/ssh/sshd_config and add the following setting:
AcceptEnv EVENTLINE EVENTLINE_*
If you want to use other environment variables in your jobs, you will have to
add them to the AcceptEnv setting as well.
Do not forget to restart the SSH daemon.
|
Warning
|
If this setting is not added, jobs using the ssh runner will fail
with the ssh: setenv failed error message.
|
Configuration
The ssh runner supports the following settings:
root_directory(optional string, default to/tmp/eventline/execution)-
The directory used to store temporary data during the execution of each job on the remote server. The path must be absolute.
Parameters
Jobs using the ssh runner support the following parameter:
host(string)-
The hostname or IP address of the server to connect to.
port(optional integer, default to 22)-
The port number to use.
user(optional string, default toroot)-
The user to connect as.
host_key(optional string)-
The expected host key of the server as a public key encoded using Base64.
host_key_algorithm(optional string)-
The algorithm of the host key if
host_keyis provided. Must be one ofssh-dss,ssh-rsa,ecdsa-sha2-nistp256,ecdsa-sha2-nistp384,ecdsa-sha2-nistp521andssh-ed25519
|
Tip
|
You can obtain the host key of a remote server using ssh-keyscan.
|
Identity
The following identities can be used with the runner:
generic/password-
Authenticate using the password in the identity. The
loginfield is ignored. generic/ssh_key-
Authenticate using the private key in the identity.
4.4. kubernetes
The kubernetes runner executes jobs in a Kubernetes
cluster. All the steps in a job are executed sequentially in the same
container of the same pod.
runner:
name: "kubernetes"
parameters:
image: "alpine:3.16"
namespace: "eventline"|
Note
|
The kubernetes runner is only available in Eventline Pro.
|
Execution
Each job is executed in a new pod and container. Eventline sets the following pod labels:
eventline.net/project-id-
The identifier of the project of the job.
eventline.net/job-name-
The name of the job.
eventline.net/job-execution-id-
The identifier of the job execution.
Execution data, including identities, are injected using a secret.
All Kubernetes resources are created with the eventline field manager. See
the
Kubernetes
documentation for more information.
Configuration
The kubernetes runner supports the following settings:
config_path(optional string)-
The path of the kubeconfig file to use to connect to the cluster. If not set, Eventline will either use the value of the
KUBECONFIGenvironment variable if it set or$HOME/.kube/configotherwise. namespace(optional string, default todefault)-
The namespace to create pods into.
Parameters
Jobs using the kubernetes runner support the following parameters:
image(string)-
The reference of the image to use for the container.
namespace(optional string)-
The namespace to create the pod into. If not set, the runner uses the namespace defined in the configuration.
labels(optional object)-
A set of name and values to be added to each created pod as labels. Values are strings.
cpu_request(optional number)-
Set the number of virtual CPUs requested for execution.
cpu_limit(optional number)-
Set a limit to the number of virtual CPUs that can be used during execution.
memory_request(optional integer)-
Set the amount of memory in megabytes requested for execution.
memory_limit(optional integer)-
Set a limit to the amount of memory in megabytes that can be used during execution.
See the Kubernetes documentation for more information regarding resource requests and limits.
Identity
The following identities can be used with the runner:
dockerhub/password-
A DockerHub username and password.
dockerhub/token-
A DockerHub username and token.
github/oauth2-
A GitHub username and OAuth2 access token for the ghcr.io image registry.
github/token-
A GitHub username and personal access token for the ghcr.io image registry.
5. Executing jobs
Jobs act as simple definitions. For their steps to be executed, they need to be instantiated. The instantiation process creates a job execution containing everything required for one run. The job execution is then stored, waiting for scheduling.
5.1. Triggers
Each job can contain a trigger which specifies when to execute it. The trigger defines an event, a set of parameters and optional additional filters. When the event occurs and filters match, Eventline instantiates the job.
If a job does not contain a trigger, it will never be instantiated automatically, but can still be executed manually.
name: "stable-branch-commits"
trigger:
event: "github/push"
parameters:
organization: "my-organization"
repository: "my-product"
filters:
- path: "/branch"
is_equal_to: "stable"
identity: "github-oauth2"See the trigger specification for a list of all trigger fields.
5.2. Events
Events represent something that happened and that was detected by Eventline. When an event is created, Eventline looks for matching triggers and instantiates associated jobs.
See the connector documentation for a list of all events in each connector.
Replay
Event replay is an advanced feature designed to help people re-execute jobs as if the original event was received again.
When an event is replayed, a new event is created with the same connector, event type and data. Eventline will look for matching triggers and execute any associated job.
This feature is particularly useful when writing complex jobs. Event replay makes it easy work on new definitions of your job. Update your job, deploy the project, and simply replay the original event to see what happens.
5.3. Manual execution
All jobs can be executed manually, either on the web interface or using the
execute-job Evcli command.
On the web interface, Eventline dynamically generates a form to provide the parameters defined by the job.
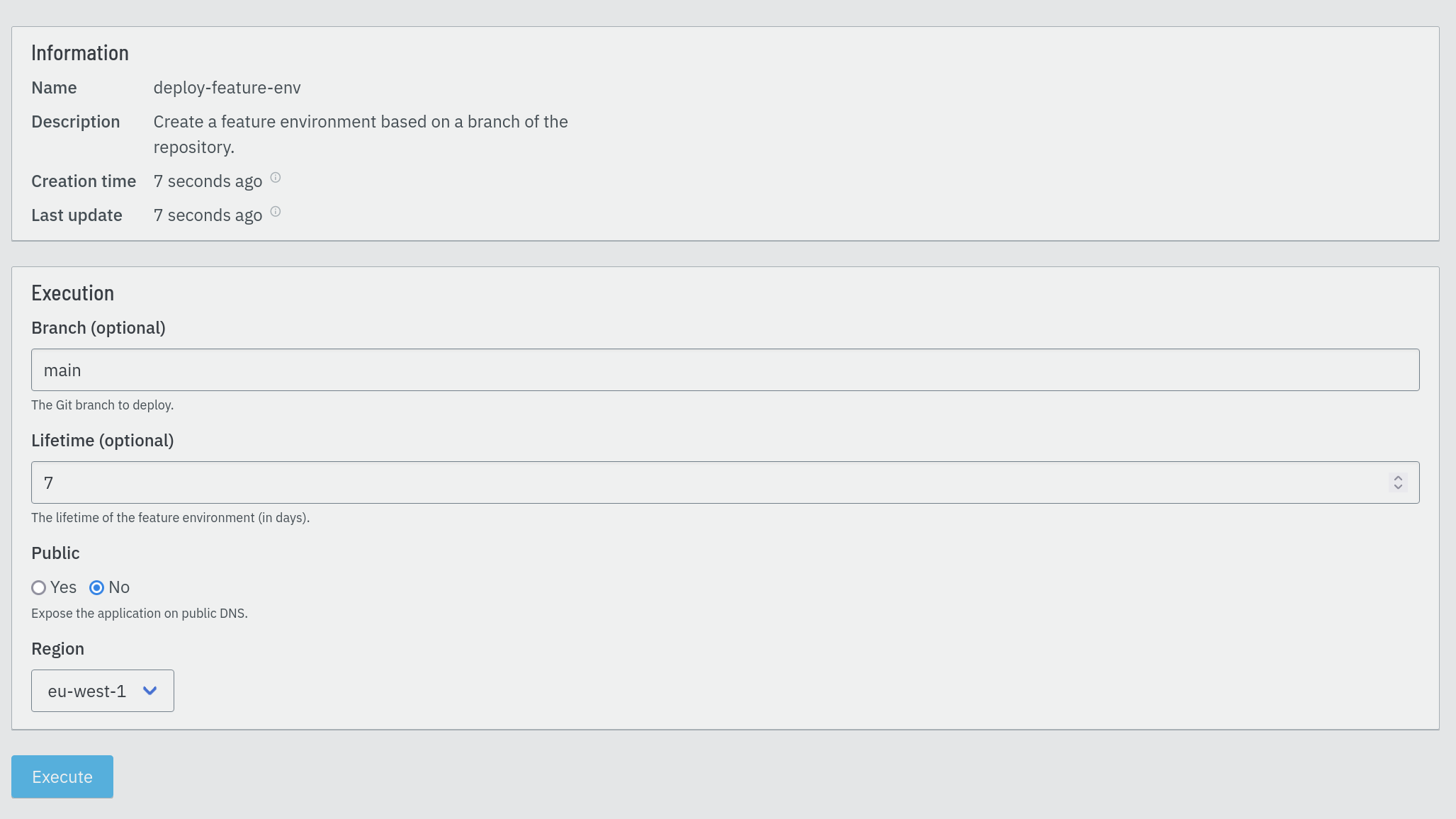
A job execution instantiated manually does not have any associated event.
|
Caution
|
If you define a job to be executable with either a trigger or manual execution, you need to make sure that the code executed by the job handle the fact that there may or may not be an available event. |
5.4. Lifecycle
Job executions have one of the following status:
created-
The job execution has just been created and is waiting for scheduling.
started-
The job execution is currently running.
aborted-
The job execution was stopped before completion, usually by an action of a user.
successful-
The job execution has completed successfully.
failed-
The job execution has failed, either because one of the steps failed or due to an internal error.
Each step in the job execution has a status code with the same possible values, allowing users to track the execution process.
Users can affect this lifecycle by aborting or restarting jobs. Both actions can be done on the web interface, with Evcli or with the HTTP API.
5.5. Timeouts
Job executions are refreshed on a regular basis once they have been started. A separate worker monitors jobs and stops those which have not been refreshed for some time. This mechanism is useful in two situations:
-
If Eventline is killed, for example due to
SIGKILLor a server failure, jobs which were running will ultimately be detected and stopped instead of staying in astartedstatus forever. -
If a runner is stuck due to an external system or because of an unexpected error, the job execution associated with it will ultimately be stopped.
This system is controlled by controlled by two settings:
job_execution_refresh_interval-
the interval between two refresh in seconds.
job_execution_timeout-
the time after which a non-refreshed job execution is considered dead in seconds.
See the configuration documentation for more information.
Abortion
Created or started job executions can be aborted. If execution has not started
yet, it will be cancelled. If the job is running, Eventline will try to
stop it. Steps which have not been executed yet will have status aborted.
Restart
Finished job executions can be restarted. When that happens, the job execution is reinitialized, ready for scheduling. Job executions are restarted using the same job specification, even if the definition of the job was changed in the mean time.
Note that the content of identities is not part of job definitions: if an identity is changed, execution after a restart will use the new set of identity data.
|
Caution
|
Eventline is a scheduling platform: jobs execute code which usually affect external systems. Restarting a job could have unexpected consequences regarding these systems. In general, writing jobs in an idempotent way will help a lot in keeping your technical processes robust. |
5.6. Runtime environment
Filesystem
All runners create and populate a directory containing various files useful during execution.
context.json-
The execution context.
parameters/-
A directory containing a file for each parameter of the job if there are any. For example, if the job has a
usernameparameter, its value is stored inparameters/username. event/-
A directory containing a file for each field in the event if there is one. For example, in a
github/rawevent, the delivery id is stored inevent/delivery_id. identities/<name>/-
A set of directories, one for each identity listed in the job, containing a file for each field of the identity. For example, if a job uses a
github/oauth2identity namedgh, the access token will be available inidentities/gh/access_token.
|
Caution
|
The location of this directory depends on the runner due to technical
limitations; always use the EVENTLINE_DIR to build paths.
|
Having event and identity fields available as simple text files makes it really simple to write jobs written as shell scripts. Using the previous example, reading the access token of the identity in shell in trivial:
access_token=$(cat $EVENTLINE_DIR/identities/gh/access_token)Alternatively, in higher level languages, simply load context.json and
access all data directly.
Execution context
The execution context is available in $EVENTLINE_DIR/context.json; the
top-level object contains the following fields:
event(object)-
The event object if the job execution was instantiated in reaction to an event.
identities(object)-
The set of all identities listed in the job.
parameters(object)-
The set of job parameters.
Environment variables
Eventline injects several environment variables during the execution of each job:
EVENTLINE-
Always set to
true, indicating that the task is being executed in the Eventline platform. EVENTLINE_PROJECT_ID-
The identifier of the current project.
EVENTLINE_PROJECT_NAME-
The name of the current project.
EVENTLINE_JOB_ID-
The identifier of the current job.
EVENTLINE_JOB_NAME-
The name of the current job.
EVENTLINE_DIR-
The absolute path of the directory containing Eventline data, including the context file.
6. Connectors
6.1. aws
The aws connector provides identities for Amazon Web Services. These
identities can also be used for AWS compatible services, for example all
services using the S3 protocol.
|
Note
|
The aws connector is only available in Eventline Pro.
|
Identities
access_key
The aws/access_key identity is used to connect to a service using the AWS
authentication system.
access_key_id(string)-
The access key identifier.
secret_access_key(string)-
The secret access key.
AWS_ACCESS_KEY_ID-
The access key identifier.
AWS_SECRET_ACCESS_KEY-
The secret access key.
6.2. dockerhub
The dockerhub connector is used to provide identities related to the
DockerHub platform.
Identities
password
The dockerhub/password identity is used for password authentication. It can
be used for authentication in runners docker and kubernetes.
It contains the following fields:
username(string)-
The username of the DockerHub account.
password(string)-
The password of the DockerHub account.
token
The dockerhub/token identity is used for access token authentication. It can
be used for authentication in runners docker and kubernetes.
username(string)-
The username of the DockerHub account.
token(string)-
The access token.
6.3. eventline
The eventline connector is used to provide identities related to the
Eventline platform itself.
It is currently only used for Eventline API keys.
Identities
api_key
The eventline/api_key identity is used to connect to the Eventline platform
with Evcli.
key(string)-
The API key.
EVENTLINE_API_KEY-
The API key.
This environment variable is used by the Evcli command line tool.
6.4. generic
The generic connector is used to provide generic identities to store
credentials for whom there are no dedicated connectors.
Identities
api_key
A generic API key.
key(string)-
The API key.
password
A generic login and password pair, the login being optional.
login(optional string)-
The login.
password(string)-
The password.
gpg_key
A GPG key.
|
Note
|
While GPG keys are technically PGP keys, the name "GPG" has become so widely used that using "PGP" would be confusing for most users. |
private_key(string)-
The private key in ASCII armor format.
public_key(optional string)-
The public key in ASCII armor format.
password(optional string)-
The password protecting the private key.
ssh_key
A SSH key.
private_key(string)-
The private key in PEM format.
public_key(optional string)-
The public key in PEM format.
certificate(optional string)-
The certificate in PEM format.
Note that OpenSSH will fail to load a private key, public key or certificate
file which does not end with a new line character (\n). Eventline will
automatically add one at the end of each field of this identity if there is
not already one present.
oauth2
The generic/oauth2 identity can be used for any platform which complies with
OAuth2 specifications. If discovery is true, Eventline will use OAuth2
discovery (RFC 8414) to find
other endpoints.
issuer(string)-
The issuer URI.
discovery(optional boolean, default tofalse)-
Whether to enable OAuth2 discovery.
discovery_endpoint(optional string)-
The URI of the discovery endpoint. Note that this field will be ignored if
discoveryis false. The default value is the endpoint mandated by OAuth2 specifications. authorization_endpoint(optional string)-
The URI of the authorization endpoint. The default value is the endpoint mandated by OAuth2 specifications or the endpoint found during discovery if
discoveryis true. token_endpoint(optional string)-
The URI of the token endpoint. The default value is the endpoint mandated by OAuth2 specifications or the endpoint found during discovery if
discoveryis true. client_id(string)-
The client identifier.
client_secret(string)-
The client secret.
scopes(string array)-
A comma-separated list of scopes to request.
access_token(optional string)-
The OAuth2 access token. Automatically handled by Eventline.
refresh_token(optional string)-
The OAuth2 refresh token. Automatically handled by Eventline.
expiration_time(optional string)-
The expiration date for the access token. Automatically handled by Eventline.
6.5. github
The github connector provides identities and events for the
GitHub platform.
Identities
oauth2
The github/oauth2 identity contains a username and an OAuth2 access token.
During the creation of the identity, you will be redirected to the GitHub website to authorize the creation of a new access token.
This identity can be used for authentication in runners docker and
kubernetes.
username(string)-
The name of the GitHub account.
scopes(string array)-
The list of OAuth2 scopes.
access_token(optional string)-
The OAuth2 access token. Automatically handled by Eventline.
refresh_token(optional string)-
The OAuth2 refresh token. Automatically handled by Eventline.
expiration_time(optional string)-
The expiration date for the access token. Automatically handled by Eventline.
GITHUB_USER-
The name of the GitHub account.
GITHUB_TOKEN-
The GitHub access token.
These environment variables are used by the official GitHub command line tool among others.
token
The github/token identity is used to store GitHub
personal
access tokens.
|
Note
|
github/token identities used in triggers require the admin:repo_hook
and admin:org_hook scopes. Using them as runner identities (e.g. for the
docker runner) will also require the read:packages scope.
|
You may need to add additional permissions if you intend to use this identity in jobs for other purposes, for example to interact with the GitHub API.
This identity can be used for authentication in runners docker and
kubernetes.
username(string)-
The name of the GitHub account.
token(string)-
The GitHub private access token.
GITHUB_USER-
The name of the GitHub account.
GITHUB_TOKEN-
The GitHub private access token.
These environment variables are used by the official GitHub command line tool among others.
Subscription parameters
organization(string)-
The name of the GitHub organization.
repository(optional string)-
The name of the repository.
Setting only organization will subscribe to events for all repositories in
the origanization, while settings both fields will subscribe to events for a
single repository.
Events
raw
The github/raw event is used to access raw data from GitHub events and is
emitted for every single organization or repository event. It can be used when
other events do not contain the required information.
delivery_id(string)-
The delivery id of the event. See the GitHub documentation for more information.
event_type(string)-
The type of the event.
event(object)-
The raw event payload delivered by GitHub.
|
Warning
|
Subscribing to github/raw events will potentially result in lots of
events created and lots of jobs executed. Make sure you actually need this
kind of low level access to event data.
|
repository_creation
The github/repository_creation event is emitted when a repository is created
in an organization.
organization(string)-
The name of the GitHub organization.
repository(string)-
The name of the repository.
repository_deletion
The github/repository_deletion event is emitted when a repository is deleted
in an organization.
organization(string)-
The name of the GitHub organization.
repository(string)-
The name of the repository.
tag_creation
The github/tag_creation event is emitted when a tag is created in a
repository.
|
Note
|
Due to a GitHub limitation, this event will not be emitted if more than three tags are pushed at the same time. |
organization(string)-
The name of the GitHub organization.
repository(string)-
The name of the repository.
tag(string)-
The name of the tag.
revision(string)-
The hash of the revision associated with the tag.
tag_deletion
The github/tag_deletion event is emitted when a tag is deleted in a
repository.
organization(string)-
The name of the GitHub organization.
repository(string)-
The name of the repository.
tag(string)-
The name of the tag.
revision(string)-
The hash of the revision associated with the tag.
branch_creation
The github/tag_created event is emitted when a branch is created in a
repository.
organization(string)-
The name of the GitHub organization.
repository(string)-
The name of the repository.
branch(string)-
The name of the branch.
revision(string)-
The hash of the revision the branch starts from.
branch_deletion
The github/branch_deleted event is emitted when a branch is deleted in a
repository.
organization(string)-
The name of the GitHub organization.
repository(string)-
The name of the repository.
branch(string)-
The name of the branch.
revision(string)-
The hash of the revision the branch pointed to when the deletion occurred.
push
The github/push event is emitted when one or more commits are pushed in a
repository.
organization(string)-
The name of the GitHub organization.
repository(string)-
The name of the repository.
branch(string)-
The branch where commits were pushed.
old_revision(optional string)-
The hash of the revision the branch pointed to before the push. This field is not set for the first push in a repository.
new_revision(string)-
The hash of the revision the branch pointed to after the push.
Examples
stable branchname: "stable-branch-commits"
trigger:
event: "github/push"
parameters:
organization: "my-organization"
repository: "my-product"
filters:
- path: "/branch"
is_equal_to: "stable"
identity: "github-oauth2"name: "new-demo-branches"
trigger:
event: "github/branch_creation"
parameters:
organization: "my-organization"
filters:
- path: "/branch"
matches: "^demo-"
identity: "github-oauth2"6.6. postgresql
The postgresql connector provides identities for the
PostgreSQL database.
Identities
password
The postgresql/password identity is used to connect to a PostgreSQL
database.
user(string)-
The PostgreSQL user.
password(string)-
The PostgreSQL password.
PGUSER-
The PostgreSQL user.
PGPASSWORD-
The PostgreSQL password.
6.7. slack
The slack connector provides identities for the Slack
platform.
|
Note
|
The slack connector is only available in Eventline Pro.
|
Identities
oauth2_bot
The slack/oauth2_bot identity is used to store
Slack bot tokens. It is
used to interact with the Slack API independently of any user account.
scopes(string array)-
The list of OAuth2 scopes.
access_token(optional string)-
The OAuth2 access token. Automatically handled by Eventline.
refresh_token(optional string)-
The OAuth2 refresh token. Automatically handled by Eventline.
expiration_time(optional string)-
The expiration date for the access token. Automatically handled by Eventline.
incoming_webhook_channel(string)-
The name of the channel associated with the incoming webhook if the
incoming-webhookscope was selected. incoming_webhook_uri(string)-
The URI of the incoming webhook if the
incoming-webhookscope was selected.
oauth2_user
The slack/oauth2_user identity is used to store
Slack user tokens. It
is used to interact with the Slack API on behalf of a specific user account.
scopes(string array)-
The list of OAuth2 scopes.
access_token(optional string)-
The OAuth2 access token. Automatically handled by Eventline.
refresh_token(optional string)-
The OAuth2 refresh token. Automatically handled by Eventline.
expiration_time(optional string)-
The expiration date for the access token. Automatically handled by Eventline.
incoming_webhook_channel(string)-
The name of the channel associated with the incoming webhook if the
incoming-webhookscope was selected. incoming_webhook_uri(string)-
The URI of the incoming webhook if the
incoming-webhookscope was selected.
6.8. time
The time connector provides a way to execute jobs using various kind of
timers.
Subscription parameters
Parameters must include one of the following fields:
oneshot(string)-
The trigger will be activated one single time. The value is a datetime string.
periodic(integer)-
The trigger will be activated at a fixed time interval. The value is the number of seconds between two activations.
hourly(object)-
The trigger will be activated every hour. The value is an object containing two optional fields
minuteandsecondindicating the precise activation time. daily(object)-
The trigger will be activated every day. The value is an object containing three optional fields
hour,minute, andsecondindicating the precise activation time. weekly(object)-
The trigger will be activated every week. The value is an object containing four fields
day,hour,minute, andsecondindicating the precise activation time. The mandatorydayfield is a string indicating the day of the week betweenmondayandsunday. Other fields are optional.
Events
tick
The time/tick event is emitted when a timer goes off.
Job triggered by time/tick events are instantiated when the timer goes off.
For non-periodic triggers, Eventline will instantiate job executions for past, missed datetimes. For example, if Eventline is down for a whole day and a job is supposed to be run every hour, it will instantiate a job execution for every hour as soon as it goes up. These executions will be queued for scheduling and executed sequentially or concurrently depending on the job definition.
|
Tip
|
In time/tick events, the event_time field is the date the timer was
supposed to go off, while the creation_time is the date the event was
actually created. You may need both values depending on the work you are
doing.
|
Examples
name: "every-5-minutes"
trigger:
event: "time/tick"
parameters:
periodic: 300name: "every-hour"
trigger:
event: "time/tick"name: "every-day-at-7am"
trigger:
event: "time/tick"
parameters:
daily:
hour: 7name: "every-friday-at-18h30"
trigger:
event: "time/tick"
parameters:
weekly:
day: "friday"
hour: 18
minute: 307. Organization with projects
It is easy to create lots of jobs and identities and end up having trouble finding what you need. To help with organization, Eventline provides a namespace mechanism, projects.
A project contains jobs and identities and keep them separate from other projects. When you are using the web interface, Evcli or the HTTP API, you only interact with a single project.
7.1. Project selection
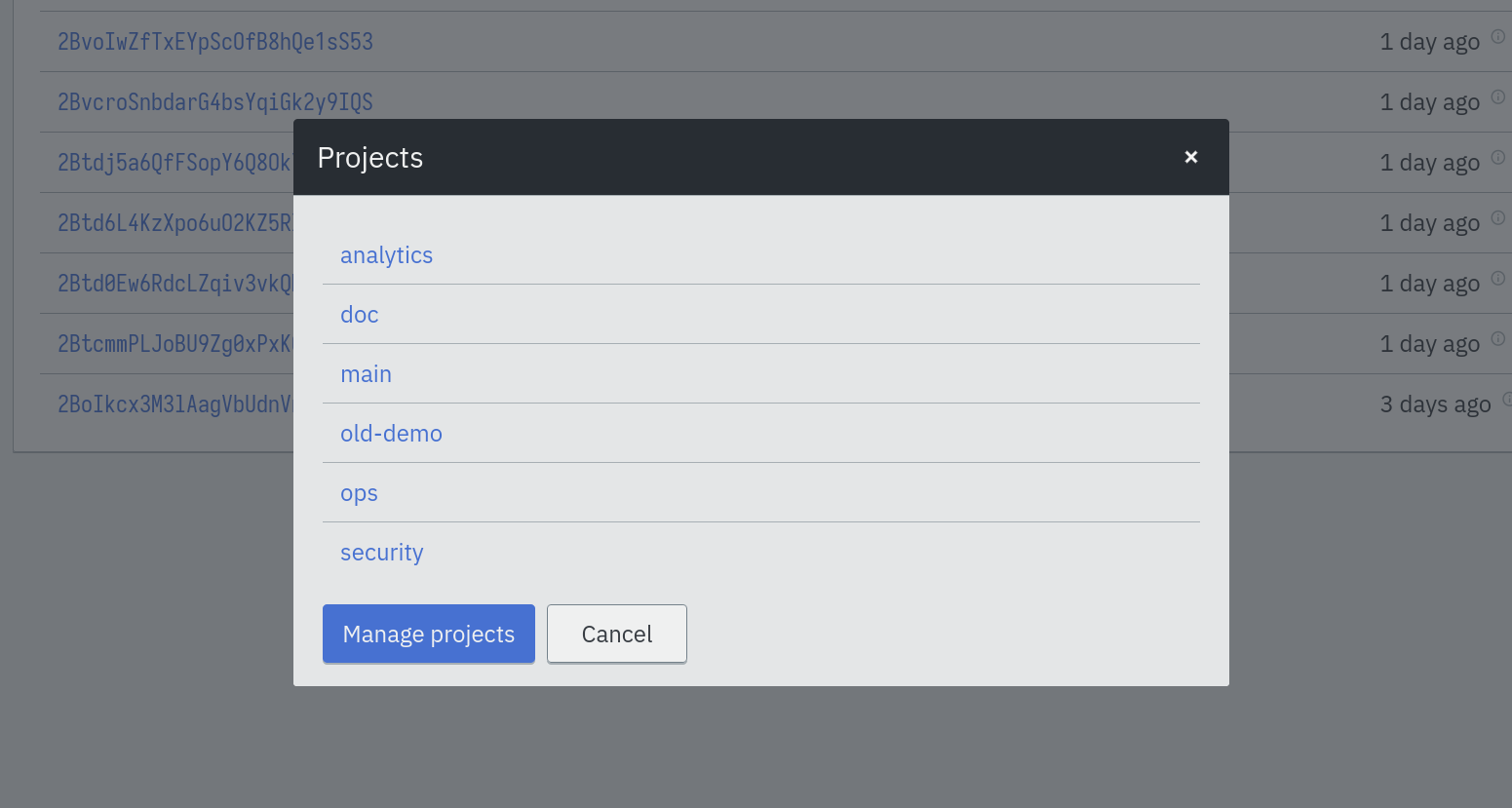
Web interface
On the web interface, you can change the current project by clicking on the project name on the top right part of the page to access to project selector:
Evcli
With Evcli, the -p, --project and --project-id options can be used to
select the project you want to interact with. Refer to the
Evcli documentation for more information.
7.2. Configuration
You can configure a project by clicking on the gear icon on the top right of the web interface.
The following settings are available:
- Code header
-
A fragment of code inserted at the beginning of each
codeblock of each step in all jobs in the project unless the block already contains a shebang line. The default value is:#!/bin/sh set -eu
7.3. Notifications settings
Each project can specify when notifications are sent.
Eventline send notifications in the following situations:
-
When jobs succeed.
-
When jobs succeed for the first time after one or more failures or abortions.
-
When jobs fail.
-
When jobs are aborted.
-
When OAuth2 identities cannot be refreshed.
You can also provide a list of email addresses to send notifications to.
|
Tip
|
If you want to send notifications to several people, e.g. an entire team, it is advised to create a user group in the software managing emails in your organization. You can then use the group address as recipient for notifications. |
8. Managing your account
8.1. Configuration
The account configuration page lets you update several settings:
- Date format
-
The format used to display dates on the web interface, either absolute (e.g. "2022-07-15T17:11:50Z") or relative (e.g. "3 hours ago").
- Default page size
-
The number of elements displayed on a page listing multiple elements, for example the event list page.
8.2. API keys
Each account can define multiple API keys. Keys are used to access the HTTP API, either using Evcli or with a client of your choice.
|
Caution
|
API key give access to your account and must be treated as sensitive data. |
Eventline only stores a cryptographic hash (SHA256) of each API key. When you create a new API key, you must save its value: you will not be able to recover it later.
API keys can be deleted at any moment to revoke access to Eventline.
9. Deployment and configuration
9.1. Requirements
Eventline is written in Go and is distributed as a statically linked executable for various platforms.
The following platforms are officially supported for production:
-
Linux x86_64.
-
FreeBSD x86_64.
Binaries are also released on a best effort basis for the following platforms:
-
Mac OS x86_64.
-
Mac OS arm64 (M1).
Eventline uses a PostgreSQL database version 14 or higher; the pgcrypto extension must be installed. It does not require local filesystem storage.
Eventline can also send metrics to an InfluxDB server.
9.2. Installation
Binary tarballs
Eventline is released primarily as a set of binary tarballs. Each tarball contains everything required to run the program:
-
Both the
eventlineand theevcliexecutables. -
The Eventline license.
-
The
datadirectory containing web assets, database migrations and template files. -
This handbook as a HTML file with associated images and javascript code.
While you can run Eventline directly from the tarball directory, you will want something more practical for production. As such, binary tarballs are generally only used by people building packages or images themselves.
Stable and experimental builds
Stable builds are derived from Git revisions tagged as
v.<major>.<minor>.<patch>. Experimental builds are derived from any other
Git revisions.
Experimental packages are made available for various platforms on a regular basis. Their goal is to allow users to try new features before they are released in a stable build.
|
Caution
|
Experimental builds are inherently less reliable than stable builds and must not be used in production. |
FreeBSD package
FreeBSD packages are available in the Exograd pkg repository. In order to install them, you first need to add the repository as a pkg source:
curl -sSfL -o /usr/local/etc/pkg/repos/exograd-public.conf \
https://pkg.exograd.com/public/freebsd/exograd.confThen you can update the package index and install Eventline:
pkg update
pkg install eventlineThe repository provides both eventline and eventline-experimental.
Ubuntu package
Ubuntu packages are available in the Exograd APT repository. In order to install them, you first need to add the repository as a source for APT:
curl -sSfL -o /etc/apt/sources.list.d/exograd-public.list \
https://pkg.exograd.com/public/ubuntu/exograd.list|
Note
|
The package repository is only available over HTTPS for security. You
will need to install the ca-certificates packages.
|
Then you can update the package index and install Eventline:
apt-get update
apt-get install eventlineThe repository provides both eventline and eventline-experimental.
Docker
If you intend to use the docker runner, you will need to install Docker. We
recommend following the
official Docker documentation.
You will also have to add the eventline user to the docker group to give
it access to the Docker socket:
usermod -a -G docker eventlineArchlinux package
Coming soon.
Docker image
The exograd/eventline image is available on
DockerHub. Versioning is the same as Eventline: for
example, Eventline 0.9.0 is available with exograd/eventline:0.9.0.
While the latest tag usually points to the latest available release, it is
strongly recommended not to use it and to always use a specific version tag to
avoid unexpected updates.
License management
Eventline Pro requires a license allowing a client to use the product.
Each client is attributed credentials provided as two values, name and secret. These values must be stored in the configuration file. See the configuration specification for more information.
Eventline Pro automatically uses these credentials to authenticate the Exograd license server and download a license file.
The license is renewed automatically at startup, and on a regular basis afterward.
Configuration
When running in this Docker image, Eventline can be configured two ways.
One way is to mount a configuration file of your choice in the container at
/etc/eventline/eventline.yaml. This gives you maximum flexibility.
An over way is to rely on the embedded configuration file which uses environment variables for configuration. The following variables are available:
EVENTLINE_WEB_HTTP_SERVER_URI(optional, default tolocalhost:8087)-
The value to use for the
web_http_server_urisetting. EVENTLINE_PG_URI(optional)-
The URI of the PostgreSQL server. The default value is
postgres://eventline:eventline@localhost:5432/eventline. EVENTLINE_ENCRYPTION_KEY-
The value to use for the
encryption_keysetting. EVENTLINE_CONNECTORS_GITHUB_WEBHOOK_SECRET-
The value of the
webhook_secretsetting for thegithubconnector. Setting this variable automatically enable the connector. EVENTLINE_MAX_PARALLEL_JOB_EXECUTIONS-
The value to use for the
max_parallel_job_executionssetting. EVENTLINE_JOB_EXECUTION_RETENTION-
The value to use for the
job_execution_retentionsetting. EVENTLINE_SESSION_RETENTION-
The value to use for the
session_retentionsetting. EVENTLINE_NOTIFICATIONS_SMTP_SERVER_ADDRESS(optional, default tolocalhost:25)-
The address of the SMTP server to use for notifications.
EVENTLINE_NOTIFICATIONS_SMPT_SERVER_USERNAME(optional)-
The username to use to authenticate to the SMTP server.
EVENTLINE_NOTIFICATIONS_SMPT_SERVER_PASSWORD(optional)-
The password to use to authenticate to the SMTP server.
EVENTLINE_NOTIFICATIONS_FROM_ADDRESS(optional)-
The email address to use in the
Fromheader field. EVENTLINE_NOTIFICATIONS_SUBJECT_PREFIX(optional)-
A character string to use as prefix for the
Subjectheader field. EVENTLINE_NOTIFICATIONS_SIGNATURE-
A character string to insert as signature at the end of all emails.
See the configuration specification for more information about settings.
Building your own image
The exograd/eventline is provided for convenience. For production use, it is
advised to build your own image. This allows you to follow the conventions
used by your organization and gives you total control on the base system,
environment and configuration.
Feel free to start from the default Dockerfile or to write your own from scratch.
Helm chart
Coming soon.
9.3. Configuration
Configuration file
Eventline uses a configuration file whose path is provided with the -c
command line option.
|
Caution
|
The configuration file contains the global encryption key used to secure storage of sensitive information in the database. You must make sure that the UNIX user executing Eventline is the only user able to read the configuration file. Alternatively, you can use templating and environment variables to provide sensitive settings. |
Templating
The configuration file is treated as a template using the Go template format. Templating currently supports the following functions:
env <name>-
Return the value of the
<name>environment variable.
data_directory: "/usr/share/eventline"
encryption_key: {{ env "EVENTLINE_ENCRYPTION_KEY" }}
pg:
uri: {{ env "EVENTLINE_PG_URI" }}At startup, Eventline loads the configuration file, renders it and then parses it as a YAML document.
Specification
A configuration file is an object containing the following fields:
logger(optional object)-
The configuration of the logger used to print information and errors. The default value is:
backend_type: "terminal" terminal_backend: color: true domain_width: 32 data_directory(optional string, default todata)-
The path of the directory containing Eventline data files.
api_http_server(optional object)-
the HTTP server configuration of the API interface. The default value is:
address: "localhost:8085" web_http_server(optional object)-
the HTTP server configuration of the web interface. The default value is:
address: "localhost:8087" pg(optional object)-
The configuration of the PostgreSQL server.
encryption_key(string)-
The global encryption key used to encrypt sensitive information in the database. The key must be a 32 byte AES key encoded using Base64. You can generate a key using OpenSSL:
openssl rand -base64 32
web_http_server_uri(optional string, default tohttp://localhost:8087)-
The URI which can be used to access the Eventline web interface from outside of the server. This URI will be used to generate webhook URIs among other thing.
insecure_http_cookies(optional boolean, default tofalse)-
If true, do not set the secure attribute for HTTP cookies sent by the web HTTP server. This allows Eventline to be used over HTTP.
CautionUsing Eventline without HTTPS is fundamentally insecure: anyone able to inspect network traffic can obtain critical information transferred between the web browser and Eventline. Do not do it. connectors(optional object)-
The configuration of each connector. Refer to the connector documentation for the settings available for each connector.
max_parallel_job_executions(optional integer)-
If set, the maximum number of jobs which can run in parallel for the entire platform.
job_execution_retention(optional integer)-
If set, a number of days after which old job executions will be deleted. Note that changing this setting will not affect job executions which have already been terminated.
job_execution_refresh_interval(optional integer, default: 10)-
The number of seconds between two job execution refresh. See execution documentation for more information on the refresh process.
job_execution_timeout(optional integer, default: 120)-
The number of seconds without refresh after which a job is considered abandonned. See execution documentation for more information on the refresh process.
session_retention(optional integer)-
If set, a number of days after which sessions will be deleted.
allowed_runners(optional string array)-
If set, a list of the runners which can be used in submitted jobs. Jobs using other runners will be rejected during deployment.
runners(optional object)-
The configuration of each runner. Refer to the runner documentation for the settings available for each runner.
notifications(optional object)-
The configuration of the email notification system. The default value is:
smtp_server: address: "localhost:25" from_address: "no-reply@localhost" subject_prefix: "[eventline] " signature: "This email is a notification sent by the Eventline job scheduling software." pro(optional object)-
Configuration specific to Eventline Pro. Ignored for the open source version.
HTTP server specification
The configuration of a HTTP server is an object containing the following fields:
address(optional string, default tolocalhost:8080)-
The address to listen on as a
<host>:<port>string. tls(optional object)-
If set, use TLS for the connection. The object contains the following fields:
certificate(string)-
The path of the TLS certificate file.
private_key(string)-
The path of the TLS private key.
PostgreSQL specification
The configuration of the PostgreSQL server is an object containing the following fields:
uri(optional string)-
The URI of the PostgreSQL server. The default value is
postgres://eventline:eventline@localhost:5432/eventline.
Notifications specification
The configuration for the notification system is an object containing the following fields:
smtp_server(optional object)-
The configuration of the SMTP server to use when sending emails.
from_address(optional string)-
The email address to use in the
Fromheader field. subject_prefix(optional string)-
A character string to use as prefix for the
Subjectheader field. signature(optional string)-
A character string to insert as signature at the end of all emails.
allowed_domains(optional string array)-
A list of domains which can used in notification email addresses. If the array is empty, all domains are allowed.
Tipthe allowed_domainssetting is useful to make sure you that all notifications are sent to email addresses you control: this way you can limit the chances of losing notifications due to a mistake, and you guarantee that you will not send emails to someone out of your organization.
SMTP server specification
The configuration of the SMTP server is an object containing the following fields:
address(optional string, default tolocalhost:25-
The address of the server using the
<host>:<port>format. username(optional string)-
The username to use for authentication.
password(optional string)-
The password to use for authentication.
Eventline Pro specification
The Eventline Pro configuration is an object containing the following fields:
license_path(string)-
The path of the license file.
license_name(string)-
The name of the license, used to authenticate against the license server.
license_secret(string)-
The secret value used to authenticate against the license server.
See documentation on license management for more information.
10. Evcli
10.1. Installation
Evcli is distributed both in binary tarballs along with the Eventline binary, and as a stand-alone executable file. Each release on GitHub contains binaries for multiple platforms which can be downloaded and used without any specific installation procedure.
Alternatively, GitHub releases contain an install-evcli executable script
which detects the operating system and architecture of the machine, downloads
the right Evcli executable and installs it.
While we try to keep Evcli both backward and forward compatible with different versions of Eventline, it is advised to use the same version for both Evcli and Eventline.
10.2. Configuration
The configuration file used by Evcli is stored in $HOME/.evcli/config.json.
You can either write it yourself, or let Evcli manage it.
|
Caution
|
The configuration file contains the API key used to connect to the
Eventline API. You must therefore make sure that other users on the same
machine cannot read it by settings file permissions to 0600.
|
10.3. Usage
Evcli supports multiple commands and options:
evcli GLOBAL-OPTIONS <command> COMMAND-OPTIONS
You can print a list of all commands with evcli -h.
10.4. Global options
The following options can be used for all commands:
--debug <level>-
Print all debug messages whose level is higher or equal to
<level>. -h,--help-
Print help about Evcli.
--no-color-
Disable the use of colors when printing data.
-p <name>,--project <name>-
Select the current project by name.
--project-id <id>-
Select the current project by identifier.
-q,--quiet-
Do not print status or information messages.
-y,--yes-
Skip all confirmation and automatically approve all questions.
10.5. Commands
abort-job-execution
Abort a specific job execution. Execution is cancelled if it has not started, and interrupted if it has.
create-project
Create a new project.
create-identity
Create a new identity. The command cannot be used to create identities which rely on a web browser for initialization, for example OAuth2 identities.
delete-job
Delete a job. All past job executions will also be deleted.
delete-identity
Delete an identity.
delete-project
Delete a project and everything it contains.
deploy-job
Deploy a single job file. The --dry-run command option can be used to
validate the job instead of deploying it.
deploy-jobs
Deploy one or more job files or directories. The --dry-run command option
can be used to validate the jobs instead of deploying them.
For each argument passed to the command:
-
If it is a file, it is assumed to be a job specification file and loaded directly.
-
If it is a directory, Evcli loads all files whose extension is
.ymlor.yamlstored inside. If the--recursiveoption is set, Evcli will recurse into nested directories.
The operation is atomic: either all jobs are deployed, or none are.
describe-job
Print information about a job.
execute-job
Execute a job. The name of the job is passed as first arguments. Additional
arguments are used to set parameter values. Each parameter value is passed as
a <name>=<value> argument.
evcli execute-job create-env branch=experimental public=true
If the --wait option is passed, Evcli will monitor execution and wait for it
to finish before exiting.
If both the --wait and --fail options are passed, Evcli with exit with
status 1 if execution fails.
export-job
Export a job to a file. The file is written to the current directory by
default. The --directory command option can be used to write to another
path.
get-config
Obtain the value from the configuration file and print it.
evcli get-config api.endpoint
help
When called without argument, print help about Evcli. When called with the name of a command as argument, print help about this command.
list-jobs
Print a list of all jobs in the current project.
list-identities
List all identities in the current project.
list-projects
Print a list of all projects.
login
Prompt for an endpoint, login and password, connects to Eventline and create an API key. The key is then stored in the Evcli configuration file.
This command is the fastest way to start using Evcli.
rename-job
Rename a job.
If the --description command option is used, also update its description.
|
Note
|
Renaming a job will affect its specification: if the job is deployed from a job specification file, you will have to update it manually. |
replay-event
Replay an event as if it has just been created for the first time. Any job whose trigger matches the event will be instantiated.
restart-job-execution
Restart a specific job execution.
set-config
Set the value of an entry in the configuration file.
evcli set-config interface.color false
show-config
Print the current configuration file as a JSON object.
If the --entries command option is used, print the list of configuration
entries as a table instead.
update
Update Evcli by downloading a pre-built binary from the last available GitHub release.
If the --build-id command option is used, download a specific version
instead.
|
Note
|
If Evcli is installed in a location which is not writable by the user
such as the path used by install-evcli (/usr/local/bin), the update
command must be executed with the appropriate permissions, for example using
sudo.
|
update-identity
Update an existing identity.
version
Print the version of the Evcli program.
11. HTTP API
The Eventline HTTP API lets users access the various features of the platform in a programmatic way.
11.1. Interface
Endpoint
The API is available on a separate endpoint. The HTTP
interface is configured by the api_http_server setting. See the
configuration documentation for more
information. The default port is 8085.
Authentication
Access to the API requires a valid API key. Authentication is
based on the HTTP Authorization header field with the Bearer scheme.
For example, for the fictional API key 082ef11a-908f-4fae-819c-eb98b7fd98f6,
requests must include the following header field:
Authorization: Bearer 082ef11a-908f-4fae-819c-eb98b7fd98f6
Project selection
Most API routes operate on a specific project. This
project must be identified in each request by sending its identifier using the
X-Eventline-Project-Id header field.
For example, for a fictional project whose identifier is
23B1NoaoigGQfmiP9PB9X2nJh4W, requests must include the following header
field:
X-Eventline-Project-Id: 23B1NoaoigGQfmiP9PB9X2nJh4W
When an API route does not depend on a project, the X-Eventline-Project-Id
can be omitted from the request.
|
Tip
|
In order to obtain the identifier of a project using its name, you can
use the GET /projects/name/{name} route to fetch the project by name and
read the id field.
|
Error handling
The Eventline API uses conventional HTTP status codes to indicate success or failure. In general, 2xx status codes indicate success, 4xx status codes indicate an error caused by the request, and 5xx status codes indicate an error in the Eventline platform.
Error responses sent by Eventline servers will contain a body representing an error object.
|
Caution
|
It is possible to receive error responses with a body which is not
encoded in JSON, for example for errors coming from a load balancer or reverse
proxy. Clients should use the Content-Type header field to determine the
format of the body. Errors originating from Eventline API servers will always
have the application/json content type.
|
Pagination
Various API routes return collections of elements. Most of these routes use pagination to group elements.
Paginated routes return a single object representing the page, i.e. the required subset of the collection of elements.
Cursors
Pagination is controlled by cursors. A cursor contains the parameters controlling the selection of elements to be returned and their order.
Each cursor contains the following parameters:
before(optional string)-
An opaque key; return elements positioned before the element designated by the key in the defined order.
after(optional string)-
An opaque key; return elements positioned after the element designated by the key in the defined order.
size(optional integer, default to 20)-
The number of elements to return, between 0 and 100.
sort(optional string)-
The sort to apply to elements. Different types of elements support different sorts; all elements support the
idsort. The default sort depends on the type of the element. order(optional string, default toasc)-
The order to use for elements, either
ascfor ascending order ordescfor descending order.
Cursors must include one and only one of the before and after parameters.
Requests
When sending requests to fetch elements, the cursor is passed using HTTP query
parameters. The before and after parameters must be Base64-encoded (see
RFC 4648).
For example, sending a request to
/jobs?after=TWpOQ2VFTlZOVVJvT1RCQ00xaFdSalJWY210WGNtNXFaRU5Q&size=5&order=id&order=desc
will result in a response containing up to 5 jobs at position
MjNCeENVNURoOTBCM1hWRjRVcmtXcm5qZENP in the whole list of pipelines ordered
by id.
All paginated requests may result in pages containing less elements that the
number required using the size parameter.
Responses
When cursors are sent in responses, for example to indicate the previous or next page, they are represented as JSON objects.
For example:
{
"after": "MjNCeENVNURoOTBCM1hWRjRVcmtXcm5qZENP",
"size": 5,
"order": "id",
"order": "desc"
}The response to a paginated query is a single page object.
11.2. Data
Data format
Unless mentioned otherwise, requests and responses contain data formatted using JSON as described by RFC 8259.
Note that as mandated by RFC 8259, JSON documents must be encoded used UTF-8 and must not start with a BOM (Byte Order Mark).
Errors
Error objects contain the following fields:
error(string)-
A human-readable description of the error.
code(string)-
An error code identifying the precise reason which caused the error.
data(optional value)-
A value, usually an object, containing additional data related to the error.
{
"error": "route not found",
"code": "route_not_found",
"data": {
"target": "\/foo\/bar"
}
}Identifiers
Most objects in Eventline are referenced by their unique identifier.
Identifiers are KSUID. They are
represented in JSON by strings containing the textual representation of the
KSUID, e.g. "23BUGaDgMUxucZnXMzyUEGRcujl".
Names
Names are used as human-readable identifiers for various elements.
Names must only contain lower case alphanumeric characters, dash characters ('-') or underscore characters ('_'); they must also start an alphanumeric character. For example, "build-archive" and "run\_http\_test\_42" are valid names; "-register" and "Send Notifications" are not. Additionally, names must contain at least one character, and must not contain more than 100 characters.
Dates
Dates are represented as JSON strings containing the RFC 3339 representation of the date and time.
For example, "2021-10-15T15:07:39Z" is a valid date.
Eventline always represents dates using Coordinated Universal Time (UTC).
Pages
The response to a paginated query is a page, represented by a JSON object containing the following fields:
{
"elements": [
{
"id": "22bQgVViNfTUAaToCrk9fMXPGsj",
"name": "project-1",
},
{
"id": "23E0dGLAnH943qkNMvMEZeFsWya",
"name": "project-2",
}
],
"next": {
"after": "MjNFMGRHTEFuSDk0M3FrTk12TUVaZUZzV3lh",
"size": 2,
"sort": "name",
"order": "asc"
}
}Accounts
Accounts are represented as JSON objects containing the following fields:
id(identifier)-
The identifier of the account.
creation_time(date)-
The date the account was created.
username(string)-
The name of the user owning the account. The username must contain at least 3 characters and no more than 100 characters.
role(string)-
The role of the account, either
useroradmin. last_login_time(optional date)-
The date of the last time someone used this account to access Eventline.
last_project_id(optional identifier)-
The identifier of the last project selected as current project for this account.
settings(object)-
An object containing settings used by the account.
Projects
Projets are represented as JSON objects containing the following fields:
id(identifier)-
The identifier of the project.
name(name)-
The name of the project.
Jobs
Jobs are represented as JSON objects containing the following fields:
id(identifier)-
The identifier of the job.
project_id(identifier)-
The identifier of the project the job is part of.
creation_time(date)-
The date the job was created.
update_time(date)-
The date the job was last modified.
disabled(optional boolean, default tofalse)-
Whether the job is disabled or not.
spec(object)-
The specification of the job. See the job documentation for more information.
Job executions
Job executions are represented as JSON objects containing the following fields:
id(identifier)-
The identifier of the execution.
project_id(identifier)-
The identifier of the project the execution is part of.
job_id(identifier)-
The identifier of the job.
job_spec(object)-
A copy of the specification of the job.
event_id(optional identifier)-
If the job execution was triggered by an event, the identifier of the event.
parameters(optional object)-
If the job was executed without any event, the set of parameters used.
creation_time(date)-
The date the execution was created.
update_time(date)-
The date the execution was last modified.
scheduled_time(date)-
The date execution is supposed to start.
status(string)-
The current status of the execution, either
created,started,aborted,successfulorfailed. See the job execution documentation for more information. start_time(optional date)-
The date execution started.
end_time(optional date)-
The date execution ended.
refresh_time(optional date)-
The date execution was last refreshed. See the job execution documentation for more information.
expiration_time(optional date)-
The date the job execution will be deleted for being too old.
failure_message(optional string)-
If execution failed, the last error message encountered.
Events
Events are represented as JSON objects containing the following fields:
id(identifier)-
The identifier of the event.
project_id(identifier)-
The identifier of the project the event is part of.
job_id(identifier)-
The identifier of the job at the origin of the event.
creation_time(date)-
The date the event was created.
event_time(date)-
The date the event actually happened.
connector(string)-
The name of the connector.
name(string)-
The name of the event.
data(object)-
The set of data contained by the event. Depends on the connector and name. See the documentation of the event in the connector section for more information.
processed(optional boolean, default tofalse)-
Whether the event was processed for job instantiation or not.
original_event_id(optional identifier)-
If the event is associated with a replayed event, the identifier of the original event.
{
"id": "22gBNze4y3o57HpES4WC8MwKvwo",
"project_id": "1zY1y6offsPNwvhFxgpteVO0GvM",
"job_id": "22g5sGMNkKvAtoH1BBMP2aDtUGb",
"creation_time": "2021-12-23T08:48:33Z",
"event_time": "2021-12-23T08:48:32Z",
"connector": "github",
"name": "push",
"data": {
"branch": "test",
"new_revision": "f1d2d2f924e986ac86fdf7b36c94bcdf32beec15",
"old_revision": "62cdb7020ff920e5aa642c3d4066950dd1f01f4d",
"organization": "example",
"repository": "my-project"
}
}Identities
Identities are represented as JSON objects containing the following fields:
id(identifier)-
The identifier of the identity.
project_id(identifier)-
The identifier of the project the identity is part of.
name(name)-
The name of the identity.
status(string)-
The current status of the identity, either
pending,readyorerror. error_message(optinoal string)-
If the identity has status
error, a description of the error. creation_time(date)-
The date the identity was created.
update_time(date)-
The date the identity was created.
last_use_time(optional date)-
The last time the identity was used.
refresh_time(optional date)-
The last time the identity was refreshed for identities which must be refreshed regularly.
connector(string)-
The name of the connector.
type(string)-
The type of the identity.
data(object)-
The set of data contained by the identity. Depends on the connector and type. See the documentation of the identity in the connector section for more information.
{
"id": "2X7hQLbWL5iQa6z17pMnXFlbqtP",
"project_id": "1zY1y6offsPNwvhFxgpteVO0GvM",
"name": "bob-account",
"status": "ready",
"creation_time": "2023-10-22T16:47:04Z",
"connector": "generic",
"type": "password",
"data": {
"login": "bob",
"password": "67d4155eb1840d15f2bb67a481d88ee5d11770081ac2a810"
}
}11.3. Routes
Accounts
GET /account
Fetch the account of the API key used to send the request. The response is an account object.
Projects
POST /projects
Create a new project.
The request must be a JSON object containing the following field:
name(name)-
The name of the project.
The response is the project object which was created.
PUT /projects/id/{id}
Update an existing project.
The request must be a JSON object containing the following field:
name(name)-
The name of the project.
The response is the modified project object.
DELETE /projects/id/{id}
Delete a project by identifier.
Jobs
PUT /jobs
Deploy a set of jobs in the current project. If jobs already exist with the same names, they are updated. If not, new jobs are created. The operation is atomic: if one of the job cannot be deployed, none will be.
The request is an array of job specification objects.
The response is an array of job objects representing the jobs created or updated from the specifications.
If the dry-run query parameter is set, Eventline validates job
specifications but does not deploy them.
DELETE /jobs/id/{id}
Delete a job by identifier.
PUT /jobs/name/{name}
Deploy a single job in the current project. If a job already exists with this name, it is updated; if not, a new job is created.
The request is a job specification object.
The response is a job object representing the job created or updated from the specifications.
If the dry-run query parameter is set, Eventline validates the job
specification but does not deploy it.
POST /jobs/id/{id}/rename
Rename a job. The request is a JSON object containing the following fields:
name(string)-
The new name of the job.
description(optional string)-
The new description of the job.
|
Note
|
Renaming a job will affect its specification: if the job is deployed from a job specification file, you will have to update it manually. |
POST /jobs/id/{id}/enable
Enable a job by identifier. Nothing is done if the job is already enabled.
POST /jobs/id/{id}/disable
Disable a job by identifier. Nothing is done if the job is already disabled.
POST /jobs/id/{id}/execute
Execute a job by identifier.
The request is a JSON object containing the following field:
parameters(object)-
The set of parameters to use for execution.
The response is a job execution object.
Job executions
GET /job_executions/id/{id}
Fetch a job execution by identifier.
The response is a job execution object.
POST /job_executions/id/{id}/abort
Abort a created or started job execution by identifier.
POST /job_executions/id/{id}/restart
Restart a finished job execution by identifier.
Events
POST /events/id/{id}/replay
Replay an event by identifier.
Identities
POST /identities
Create a new identity.
The request must be a JSON object containing the following field:
name(name)-
The name of the identity.
connector(string)-
the name of the connector.
type(string)-
the type of the identity.
data(object)-
the set of data associated with the identity.
The response is the identity object which was created.
|
Note
|
Identities requiring a web browser such as OAuth2-based identities cannot be created using the API. |
PUT /identities/id/{id}
Update an existing identity.
The request must be a JSON object containing the following field:
name(name)-
The name of the identity.
connector(string)-
the name of the connector.
type(string)-
the type of the identity.
data(object)-
the set of data associated with the identity.
The response is the modified identity object.
DELETE /identities/id/{id}
Delete a identity by identifier.
12. HOWTO
This chapter contains various examples and ideas designed to help users accomplish specific tasks. Most of them come from questions asked by users; if you are not sure about how to do something, just ask!
12.1. How to use a private Docker image registry
Use a runner identity to authenticate against the Docker registry. For
example, to use the GitHub image registry, you can use a
github/token identity:
name: "my-job"
runner:
name: "docker"
parameters:
image: "my-org/my-private-image:latest"
identity: "my-github-token-identity"Refer to the runner documentation for more information about identities supported for each runner.
12.2. How to use other languages than the shell
Code steps are executed as any other code file. If there is no
Shebang, Eventline add the one
configured by default in the project, which happens to be /bin/sh.
To use any other language, just include your own shebang.
For example, to run Python code:
name: "my-job"
steps:
- code: |
#!/usr/bin/python
puts("Hello world!")See the job documentation for more information.
12.3. How to use a SSH key in a job
SSH keys are stored in generic/ssh_key identities. The
field used to authenticate is private_key.
Since identity fields are injected in jobs as files, you can access the
private key at $EVENTLINE_DIR/identities/<identity-name>/private_key.
The simplest way is to link the files as the default SSH key. For example, if you are using a RSA SSH key:
ln -s $EVENTLINE_DIR/identities/<identity-name>/private_key ~/.ssh/id_rsaYou can of course use the private key file, for example for the -i option of
ssh and scp.
12.4. How to clone a private GitHub repository
Private GitHub repositories are accessed with a SSH key. You can link the
private key as the default SSH key, then simply call
git clone:
ln -s $EVENTLINE_DIR/identities/<identity-name>/private_key ~/.ssh/id_rsa
git clone git@github.com:my-organization/my-repository.git